Quantum kernels in solving differential equations

Machine learning is often guided by the balance between bias and variance, i.e. if a model is too simple, it struggles to capture the underlying relationships between inputs and outputs and, on the other hand, a model that's too complex might excel during training but falter when faced with new, unseen data.
Ideally, we aim for models that are both quick to train and sophisticated enough to discover meaningful patterns and one of the most intriguing methods to achieve this balance is through kernel methods which allow for the training of simple linear models that maintain low bias and low variance, by mapping the data into a higher-dimensional feature space, making them both efficient and effective. In this post, after a brief introduction, we'll discuss the fascinating world of quantum kernels (which as the name suggests are the quantum analogue of kernel) and explore how these powerful tools can be applied to solve differential equations.
Kernel methods
Kernel methods are a cornerstone of machine learning, providing a powerful way to handle non-linear relationships between output ($y$) and input data($x$). The core idea is to transform the data into a higher-dimensional feature space where linear models can be applied effectively. This transformation is not done explicitly, instead, the so-called kernel trick allows to compute inner products between data points as if they were in the higher-dimensional space, without ever needing to compute their actual coordinates in that space. This results in computational efficiency, even when working with very high-dimensional spaces.
We can use kernel methods in a regression context, i.e. to find a function $f$ s.t.:
$$f(x_i) \approx y_i$$
where \(x_i\) are the input features and \(y_i\) are the corresponding output labels.
For example one may assume the $f$ has to be linear, i.e.
$$f(x) = a+x b$$
where $a$ and $b$ are just vectors that can be learned by minimizing an error function, for example the mean square error:
$$MSE = \frac 1n \sum_i (f(x_i)-y_i)^2$$
Of course assuming a linear relation between the input and the output isn’t necessarily true and while such a linear model is a really simple model, it could struggle with non linear data.
To address such non-linear relationships, kernel methods extend the idea of linear models by mapping the input space $x$ to a higher-dimensional feature space \(\phi(x)\) choosing \(\phi(\cdot)\) s.t. $y$ is then linear in \(\phi(x)\) and linear models can be used.
However the strength of kernel methods lies in the already mentioned kernel trick: instead of explicitly calculating the new feature space, kernel methods relies on the so called kernel functions:
$$K(x_i, x_j) = \langle\phi(x_i), \phi(x_j)\rangle$$
which is the used to define the kernelized learning task, which could potentially be something like:
$$f(x) = \sum_i a_i K(x, x_i) + b$$
which is linear in the newly mapped feature space. At that point an error function can be defined to find the parameters of the model.
As you can see the essence of the kernel methods relies in their ability to handle non-linear data using linear models in a higher-dimensional space without explicitly mapping data to that space.
One last point: in functional analysis, Mercer theorem guarantees that, if some condition are met, a dot product in some Hilbert space corresponds to a kernel. This is of paramount importance as one may define a kernel function from an inner product as we will do later in the article to get a quantum kernel.
Kernel methods in Python
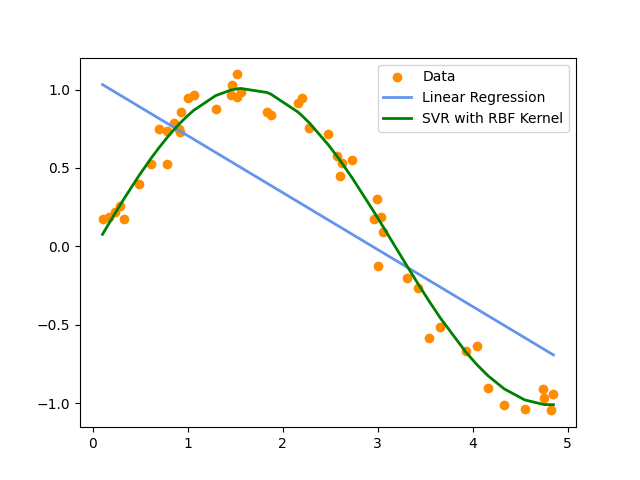
To make it easier for the reader to understand kernel methods, I prepared a simple python example where linear regression and a particular kernel method is applied on non-linear data:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
# Create non-linear data
np.random.seed(42)
X = np.sort(5 * np.random.rand(50, 1), axis=0)
y = np.sin(X).ravel() + np.random.normal(0, 0.1, X.shape[0])
# Fit Linear Regression
linear_reg = LinearRegression()
linear_reg.fit(X, y)
y_pred_linear = linear_reg.predict(X)
# Fit Support Vector Regression (SVR) with RBF Kernel
svr_rbf = SVR(kernel='rbf', C=100, gamma=0.1, epsilon=0.1)
svr_rbf.fit(X, y)
y_pred_svr = svr_rbf.predict(X)
# Plot the results
plt.scatter(X, y, color='darkorange', label='Data')
plt.plot(X, y_pred_linear, color='cornflowerblue', label='Linear Regression', linewidth=2)
plt.plot(X, y_pred_svr, color='green', label='SVR with RBF Kernel', linewidth=2)
plt.legend()
plt.show()
The result of the above code is:
Quantum kernel methods
Quantum kernel methods take the idea behind classicalMkernels to the next level, using quantum mechanics to tackle more complex, high-dimensional data. The basic idea is to encode information into quantum states and calculate similarities in the new space. This section discusses quantum kernel methods, starting from the encoding of the classical variables into quantum states and then discussing the evaluation of quantum kernel functions and how to take derivatives of quantum kernel functions.
Encoding
We start introducing the concept of quantum kernel methods from that of quantum kernel function. As already mentioned, a kernel function is a function $k$ mapping two variables \(x_i\) \(x_j\) \(\in\) $A$ to the complex space:
$$k: A \times A\rightarrow \mathbb{C}$$
and a quantum kernel function is a kernel function that can be evaluated on a quantum computer. For example a valid quantum kernel can be:
$$k(x_i, x_j) \equiv \bra {\psi(x_i)}\ket {\psi(x_j)}$$
where the \(\psi(x_i)\) indicates a quantum states encoded by the classical variable \(x_i\).
To define quantum kernel functions properly, it's essential to understand what encoding into quantum states entails and how to do it efficiently which is equivalent to the crucial task of designing an efficient feature map. The idea is to use a parametrized quantum circuit $U$ s.t.:
$$U(x_i)\ket 0 = \ket {\psi(x_i)}$$
A simple example of $U$ is:
$$\bigotimes_j R_{p,j}[\phi(x_i)]$$
where \(R_{p,j}[\phi(x_i)]\) represents the rotation on qubit $j$ of angle \(\phi(x_i)\)over about a Pauli operator $q$. The selection of the feature map is crucial, as it must be expressive enough to capture the problem's solution while remaining trainable.
Evaluation
After mapping the classical variables into the feature space, the next step is to efficiently implement the quantum kernel function in a quantum circuit. Given that a convenient quantum kernel is defined as:
$$k(x_i,x_j) \equiv |\bra {\psi(x_i)}\ket {\psi(x_j)}|^2$$
the question becomes: which quantum circuit can perform this computation?
Naively, one can exploit the fact that:
$$k(x_i,x_j) \equiv |\bra {\psi(x_i)}\ket {\psi(x_j)}|^2= \bra 0U^\dagger(x_j)U(x_i)\ket0\bra 0U^\dagger(x_i)U(x_j)\ket0$$
which can be implemented by applying \(U(x_j)\) followed by \(U(x_i)\) on \(\ket 0 ^{\otimes n} \) , where $n$ is the number of qubits necessary to encode \(\ket {\psi(x)}\), followed by measurements. The kernel function value is determined by measuring all qubits and calculating the probability of remaining in the zero state, which is found by taking the ratio of times \(\ket 0\) is found.
Alternatively, one may use the coherent SWAP test (while this would require \(2n +1\) qubits). This involves preparing the \(\ket {\psi(x_i)}\)and \(\ket {\psi(x_j)}\) states on two separate registers and then performing a swap controlled by an ancilla in superposition. The advantage of this method is that it only requires to measure one single ancilla qubit, however it needs more qubits than the naïve method above.
Last, it is possible to use two evaluations of the Hadamard test (which requires \(n+1\) qubits) which can be exploited to compute the real and the imaginary part of:
$$\bra 0U^\dagger(x_i)U(x_j)\ket0$$
which are then used to evaluate the kernel as:
$$Re( \bra 0U^\dagger(x_i)U(x_j)\ket0 )^2 + Im( \bra 0U^\dagger(x_i)U(x_j)\ket0 )^2$$
Computing derivatives
Since this article involves solving differential equations, we need to be able to compute the derivatives of the kernel function on a quantum computer. This will be important for the definition of the loss function and for the optimization of the parameters of the solution.
Let’s first assume that:
$$\nabla_{p,q} k(x_i,x_j) \equiv \frac{\partial^{p+q} k(x_i,x_j)}{\partial^p x_i\partial^qx_j}$$
We can consider the kernel function formulation acting on a single register defined above (the one we called naïve):
$$k(x_i, x_j)=\bra 0U^\dagger(x_j)U(x_i)\ket0\bra 0U^\dagger(x_i)U(x_j)\ket0$$
and build the following quantum model:
$$f(x) = \bra 0U^\dagger(x)MU(x)\ket0$$
where $M$ is a measurement operator and take its derivative, which, by parameter shifting rule (a method for estimating the gradients of a parameterized quantum circuit, which will be the focus of one of the upcoming articles) is:
$$\partial_xf=\sum_{i=1}^n\frac{f(x+\frac \pi 2_i) - f(x-\frac \pi 2_i)}2$$
where $n $ is the number of gates depending on $x$ in $U(x)$ and \(f(x\pm\frac \pi 2_i)\) is the evaluation of $f(x)$ where the i-th gate depending on $x$ is shifted by \(\pm\frac \pi 2\). Higher order derivatives can be implemented iterating the parameter shifting rule.
Alternatively the computation of derivatives is also permitted by the Hadamard test. Starting once again from:
$$k(x_i, x_j)=\bra 0U^\dagger(x_j)U(x_i)\ket0\bra 0U^\dagger(x_i)U(x_j)\ket0$$
by product rule the first derivative is:
$$\bra 0U^\dagger(x_j)\partial_{x_i}U(x_i)\ket0\bra 0U^\dagger(x_i)U(x_j)\ket0 + \bra 0U^\dagger(x_j)U(x_i)\ket0\bra 0\partial_{x_i}U^\dagger(x_i)U(x_j)\ket0$$
and the first term can be computed via Swap test while the second one via one or more Hadamard tests.
Solving differential equations
This section deals with describing how quantum kernels can be used as solvers for differential equations. The first subsection introduces a regression method and the second subsection applies it to solve differential equation.
Mixed model regression
In the context of mixed model regression, the trial function (the functional form we give to the solution) is:
$$f_a(x) = b + \sum_{j=1}^na_j k(x, y_j)$$
where \(k(\cdot)\) is the quantum kernel function, \(\{y_j\}\) is a set of evaluation points, $a$ and $b$are tunable coefficients. It’s worth noticing that being $a$ the parameter to be optimized and since \(k(x, y_j)\) is independent of $a$, one can compute each \(k(x, y_j)\) before starting the optimization procedure. Moreover, one of the advantages of mixed model regression is that its structure remains consistent across different problems, whereas in other classes of kernel regressions (e.g. support vector regression), the model form can vary.
Differential equations
Let the following differential equation for the sake of simplicity:
$$DE(f,x, \partial _xf)= \partial_x f - g(f, x) = 0$$
with\(f(x_0) = f_0\), where $g$ is a smooth function, we want to use mixed model regression and support vector regression to solve this DE.
Starting from mixed model regression, a proper choice for the loss function is:
$$\mathcal L(a) = \sum_i \left [ DE\left(f_a,x_i, \partial _xf_a(x_i)\right] \right ) + (f_a(x_0) - f_0)^2$$
where:
$$f_a(x) = b + \sum_{j=1}^na_j k(x, y_j)$$
Since the kernel and it’s derivatives are independent of $a$, they can be evaluated only once and, using an appropriate optimization technique, it’s possible to find the optimal weights $a$. Moreover in some cases such optimization problem is convex. The resulting function is then a suitable approximation to the solution of the differential equation.
In the case the differential equation is different from the one in the above example, one may rely on the same framework, just adjusting for generalized optimization (i.e. by defining a suitable loss function and by minimizing the sum of different loss functions in the case of systems of differential equations).
And that's it for this article. Thanks for reading.
For any question or suggestion related to what I covered in this article, please add it as a comment. For special needs, you can contact me here.




